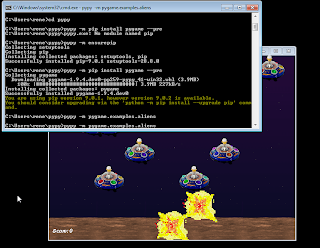
🐱🏍 — the first pygame 2 community game. Starting now! Are you in?
What is a 🐱🏍? *[0]. There was this email thread on the pygame mailing list. " About Pygame development ". One topic of that conversation was doing a community game in there for reasons(see below). I would like to do a pygame 2 community game to submit in the: - https://ldjam.com/ - https://itch.io/jam/game-off- 2018 (GameOff github jam) Ludumdare(ldjam) starts in 3 days, 7 hours. Theme not selected yet. GameOff finishes in 4 days 2 hours. Theme is "Hybrid ", Jam already started. So, the Jams finish in 4.1 days. Are you in? If so join the web based chatroom (discord) in the "#communitygame" channel. Our repo: https://github.com/pygame/stuntcat I'm trying to form a team now. ... read more?... click.... loading... loading... buffering... loading... refresh... loading... So why do this? My reasons for doing this are to push me to get pygame 2 features done that are actually u...